


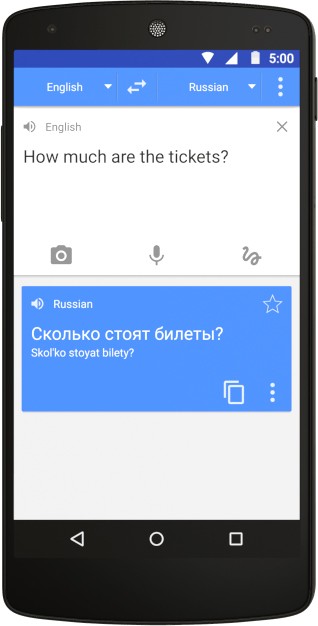
Google 翻訳 (GT) は間違いなく世界で最高で最も使用されている翻訳ソフトウェアです。最大 103 の言語、10,000 の言語ペアをサポートし、毎日 5 億件もの翻訳を処理します。専門家らは、GTのニューラルシステムが間もなくテキストだけでなくオーディオファイルやビデオファイルも処理できるようになるだろうと予測している。
Googlov prevajalnik (Google Translate) od leta 2016 uporablja prevajalni sistem nevronskih strojev (Neural Machine Translation System – GNMT). Sistem, ki temelji na umetni nevronski mreži, je bistveno izboljšal kakovost prevajanja. Od takrat so minila tri leta, in sedaj lahko ocenimo njegovo učinkovitost. Se je kvaliteta prevodov res izboljšala in kaj je še potrebno spremeniti, da se bo izboljšala?
Kako sploh deluje algoritem Googlovega prevajalnika?
Googlov prevajalnik (Google Translate) so razvili leta 2006 in je sprva deloval s pomočjo statistične metode strojnega prevajanja. To pomeni, da je v svoj program shranil milijarde in milijarde besed. Pri prevajanju pa je enostavno izbiral najustreznejše ali najbolj priljubljene ekvivalente obeh jezikov in jih izpisal. Google je pri izdelavi prevajalnika uporabljal dokumente Združenih narodov (angleščina, arabščina, francoščina, kitajščina, ruščina in španščina) in tako izdelal korpus šestih svetovnih jezikov s približno 20 milijardami besed. Ta postopek je bil počasen, netočen in je porabil veliko računalniške moči.
Danes Googlov prevajalnik uporablja tako imenovano metodo globokega učenja (Deep Learning Method), pri kateri je pomembna predvsem velika umetna nevronska mreža.
Preden so pri Googlu začeli uporabljati nevronsko mrežo, je prevod potekal besedo za besedo. Sistem je enostavno prevedel vsako besedo posebej, ob tem pa upošteval osnovna slovnična pravila. Zato je bila kakovost prevoda zelo vprašljiva.
Pri novem, nevronskem modelu prevajanja, pa osnovna prevajalska enota ni več beseda, ampak le del besede. Tako prevod ni osredotočen na besedne oblike, temveč na kontekst in pomen celega stavka. Program torej prevede stavek kot celoto, glede na njegov kontekstualni pomen, pri čemer v svoj spomin ne shranjuje na stotine možnih prevodnih različic.
Programska oprema torej prevede celoten stavek z upoštevanjem konteksta, in se ne osredotoča več le na posamezne besede. V svoj spomin ne shrani več sto prevodnih različic. Namesto tega deluje glede na semantiko besedila in stavke deli na slovarske segmente.

Kako Google prevaja s pomočjo nevronske mreže?
Danes Googlov prevajalnik uporablja približno 32.000 takšnih fragmentov. S pomočjo posameznih dekoderjev sprva določi pomen vsakega dela besedila. Nato izračuna največje možno število pomenov in možnih prevodov. Na koncu pa združi prevedene segmente s slovničnimi pravili. Kot pravijo razvijalci, ta pristop omogoča zagotavljanje visoke hitrosti in natančnosti prevajanja brez porabe prekomerne računalniške moči. Ker pa ima vsak jezik svoje zakonitosti (pomenske in slovnične), potrebuje Googlov prevajalnik za vsak jezik tudi posebne module in slovarje, ki se izvajajo v ločenih algoritmih.
Interlingua
Umetna inteligenca, ki jo uporablja Googlov prevajalnik kot vmesni jezik, se imenuje Interlingua. Ta univerzalni računalniški jezik je seveda povsem neprimeren za komunikacijo med ljudmi. Umetni inteligenci pa služi pri prevajanju, kjer ga uporablja kot vmesni jezik, s katerim lahko prevaja tudi v in iz jezikov za katere ni bila ustvarjena.
Prednost nevronske mreže je v tem, da lahko operira z večjim številom jezikovnih parov, tudi s tistimi, ki niso bili vključeni v prvotni učni proces. Na primer, če je bil sistem naučen, da prevaja jezikovna para angleščina-japonščina in angleščina-korejščina, lahko enostavno prevaja tudi jezikovni par japonščina-korejščina, brez da bi kot vmesni jezik uporabljal angleščino.
Prevajalsko metodo, ki so jo implementirali pri Googlu, so razvijalci poimenovali prevod z “nič-zadetkov” (zero-shot), je bolj prefinjena in se pri prevodu zanaša na vmesni umetni jezik. To področje raziskovanja se zelo hitro razvija, in kmalu bodo ti prevajalski sistemi postali primarno orodje prevajanja. Sistem je namreč samouk – sam nadgrajuje svoje znanje in lahko pravilno prevaja tudi slegovske in žargonske besede, neologizme in ostale besede, ki niso vključene v splošne slovarje.

Jezikovni pari
Sistem GNMT je zelo izboljšal prevajanje najbolj pogosto uporabljenih jezikovnih parov: španščina-angleščina in pa francoščina-angleščina. Pravilnost prevodov se je povečala na kar 85%.
Leta 2017 so pri Googlu naredili raziskavo med rednimi uporabniki prevajalnika. Prosili so jih naj ocenijo tri prevajalske možnosti: strojna statistična, nevralna in človeška. Rezultati so bili impresivni – prevodi, ki so bili narejeni z nevronsko mrežo, so bili v nekaterih jezikovnih parih skoraj popolni.
Očitno je, da je kvaliteta prevodov v jezikovnih parih angleščina-španščina in francoščina-angleščina skoraj enako ocenjena, kot pri prevodih, ki jih naredi človek. To dejstvo pa ne preseneča, saj so bili ti jezikovni pari uporabljeni za globoko učenje algoritmov Googlovega prevajalnika. Pri drugih jezikovnih parih je situacija drugačna. Vendar, če nevronski prevod med strukturno podobnimi jeziki deluje primerljivo, potem bo pri jezikovnih parih, pri katerih so jezikovni sistemi radikalno drugačni, računalniški prevod mnogo slabši.

Kakšne so pomanjkljivosti Googlovega prevajalnik?
Res je, da je Googlov prevajalnik zelo praktičen, in je zaradi svoje dostopnosti in hitrega delovanja v pomoč pri vsakodnevnem prevajanju. Vendar pa mu še vedno manjka nekaj bistvenega – 理解. Računalniški prevod namreč nikoli ni osredotočen na razumevanje. Razvijalci programa so poskušali izboljšati metodo dešifriranja oziroma povedano drugače, poiskušali so doseči, da bi se stroj prevoda lotil s svojimi analitičnimi sposobnostmi. Vendar pa so morali najti ravnovesje med točnostjo in hitrostjo prevoda.
Učinek Eliza
Za katerikoli stroj, računalniško napravo ali programsko opremo, so besede pomembne. Vendar pa stroji zaenkrat še ne morejo razumeti globokega pomena besed.
年 1960 so naredili Elizo, mehansko napravo, ki je manipulirala z vrsto odgovorov, in s tem dajala vtis da dejansko ustvarja inteligentne fraze. Od takrat naprej je vprašanje o tem, ali stroji lahko razmišljajo kot ljudje, poimenovan učinek Eliza.
Učinek Eliza je desetletja vplival na raziskovalce umetne inteligence in razvijalce programske opreme. Večina uporabnikov Googlovega prevajalnika verjame, da je ta program, vsaj včasih, sposoben razumeti pomen besed. Vendar to ne drži – Googlov prevajalnik jezika ne razume, vendar mu kljub temu včasih uspe skovati stavke, ki zvenijo kar dobro. Včasih mu uspe celo, da odlično prevede celo odstavek ali dva, in že skoraj verjamemo, da program dejansko razume jezik. Vendar ne smemo pozabiti, da Googlov prevajalnik ni sposoben razmišljati kot človek in lahko besedila procesira le na točno določen način. Računalniški program nima spomina, nima domišljije in ne razume skritih pomenov besed.Torej, ni razloga, da ne bi verjeli, da bodo računalniki nekoč v prihodnosti, lahko razmišljali kot ljudje.
Pričakuje pa se, da bodo sposobni odličnih prevodov med različnimi jeziki. Zelo verjetno je, da bodo namreč nekoč sposobni prevajati vice, novele, poezijo in eseje. Navsezadnje se tehnologija razvija s svetlobno hitrostjo.
詳しくは:
translate.google.com

